# Connaissances de base
Ce chapitre vous présente les connaissances de base relatives à l'automatisation Android. Assurez-vous de lire attentivement la description de ce chapitre, car elle ne sera pas répétée par la suite. L'automatisation Android présente des différences significatives par rapport à l'automatisation web conventionnelle, mais elles partagent également de nombreux points communs. Dans l'automatisation web classique, il est très simple d'inspecter la mise en page d'une page web et les informations telles que les ID d'éléments à l'aide des outils de développement F12, puis d'utiliser XPATH pour obtenir des éléments et effectuer des opérations telles que des clics et des attentes. Bien sûr, la logique est similaire sur Android, où vous pouvez également utiliser ce qu'on appelle un sélecteur pour sélectionner des éléments et effectuer des opérations de clic, de vérification, etc. Vous n'avez donc pas à vous inquiéter de la difficulté à démarrer.
## Similitudes et différences entre l'automatisation mobile et web
L'automatisation mobile et l'automatisation web ont de nombreux points communs, mais aussi de nombreuses différences. Prenons Selenium comme exemple. Habituellement, pour contrôler une page web avec Selenium, vous avez besoin de trois choses : un navigateur, un webdriver et Selenium. Il en va de même pour le mobile : le téléphone mobile équivaut au navigateur, FIRERPA équivaut au webdriver, et la bibliothèque Python de FIRERPA, c'est-à-dire lamda, équivaut à Selenium. De plus, leur objectif est le même : simuler les actions de l'utilisateur pour réaliser des tests, collecter des données ou exécuter des tâches automatiquement. Tous deux sont pilotés par des scripts et effectuent des opérations telles que la localisation d'éléments, les clics, les captures d'écran et les vérifications. Vus sous cet angle, ils sont en fait assez similaires.
Cependant, ils sont également différents. Tout d'abord, l'automatisation mobile nécessite que vous disposiez d'un téléphone et d'un ordinateur, tandis que l'automatisation web peut être réalisée sur votre propre ordinateur. De plus, ils n'utilisent pas la même approche. Pour le web, les outils courants sont Selenium, Puppeteer, Playwright. Pour le mobile, ce sont généralement FIRERPA, AutoJS, Appium, uiautomator, etc.
Pour le web, les méthodes de localisation courantes sont principalement basées sur la structure du DOM HTML, comme xpath ou csspath, et la hiérarchie des éléments est relativement intuitive. Pour le mobile, la méthode de localisation courante est le sélecteur. Bien sûr, les interfaces des applications Android utilisent également une mise en page XML, vous pouvez donc aussi utiliser XML pour la sélection xpath. En général, l'automatisation web n'a pas à se soucier de trop de problèmes de compatibilité ; dans la plupart des cas, on peut contourner la plupart des problèmes de compatibilité liés à l'appareil en fixant le navigateur et la résolution de démarrage. Mais pour Android, en raison des différences entre les marques et les modèles d'appareils, la taille de l'écran, la version du système, etc., peuvent toutes avoir un impact sur la compatibilité du code d'automatisation. Mais ne vous inquiétez pas, bien qu'il y ait un impact, il n'est pas majeur.
## Différences entre les divers outils d'automatisation
Comme mentionné précédemment, il existe également de nombreuses différences entre les outils d'automatisation Android courants que nous avons cités. Précisons d'emblée notre position : FIRERPA est le plus stable, le plus complet, le plus puissant et le plus adapté à la gestion et à l'application de projets parmi tous les outils d'automatisation.
```{note}
Notre position n'est pas un préjugé, mais le résultat de 6 ans d'exploration et d'optimisation continues. Nous avons parcouru la plupart des chemins et rencontré les mêmes écueils que vous.
```
### AutoJS
Les produits dérivés courants comme AutoJS appartiennent à la catégorie de l'auto-contrôle. Ils nécessitent l'installation d'un APK sur l'appareil et l'écriture de scripts en JS pour fonctionner. En général, AutoJS ne peut effectuer que des opérations de niveau automatisation. Son avantage est qu'il convient aux débutants ou à un usage amateur, avec une faible barrière à l'entrée. Cependant, sa conception n'est pas adaptée au contrôle, à la gestion et à la mise à jour de scripts à grande échelle. Il est décentralisé et non géré, ce qui empêche un contrôle précis à grande échelle.
### Appium
Appium, couramment utilisé par les testeurs, a une architecture C/S. Il est relativement plus adapté au contrôle de clusters qu'AutoJS, mais il présente des inconvénients évidents. Comme il est conçu pour l'automatisation de la plupart des systèmes, prenant en charge non seulement Android mais aussi iOS, il est volumineux et lourd, ce qui le rend très inadapté au déploiement à grande échelle.
### u2
Enfin, uiautomator2, également d'architecture C/S, est plus précis qu'Appium et suffisamment léger, sans trop de fonctionnalités superflues, et ses fonctions sont juste ce qu'il faut. Mais pourquoi l'avons-nous abandonné ? La raison principale est son manque de stabilité dans un environnement multi-appareils. De plus, sa logique d'installation automatique, bien que pratique pour les débutants, est superflue et difficile à maîtriser pour un contrôle de cluster professionnel, et il n'est plus maintenu.
Bien sûr, ils sont tous très adaptés à un usage courant. Mais il se trouve que notre approche n'est pas très conventionnelle, car dans le monde des affaires, il est généralement impossible de se limiter à l'automatisation. Par exemple, imaginez une tâche : tester une certaine application et enregistrer les requêtes, les réponses, les temps de requête, etc. Comment feriez-vous ? Je pense que votre solution impliquerait soit beaucoup d'opérations manuelles supplémentaires, soit serait extrêmement instable ou incompatible. Dans le monde de FIRERPA, vous pouvez effectuer toutes les opérations avec du code. Vous n'interagissez qu'avec du code, et la stabilité et la compatibilité sont gérées par FIRERPA. En fait, nous ne devrions pas nous comparer à ces outils, car en termes de fonctionnalités, FIRERPA est un sur-ensemble de toutes les solutions mentionnées ci-dessus ; il intègre toutes les leçons que nous avons apprises de nos erreurs et de notre parcours.
## Flux de travail de base de l'automatisation
Habituellement, vous devez d'abord étudier la solution à mettre en place : s'agit-il uniquement d'une automatisation classique ou faut-il également extraire des données d'exécution de l'application en même temps que l'automatisation ? En général, vous avez deux options pour l'extraction de données. La première consiste à intercepter les communications HTTP/s via un homme du milieu (Man-in-the-Middle). La seconde consiste à intercepter les données via le Hooking. La méthode de l'homme du milieu est plus simple et convient à un usage courant, mais elle peut ne pas fonctionner avec certaines applications. La solution de Hooking nécessite des connaissances approfondies en ingénierie inverse, ce qui la rend difficile pour les débutants et plus adaptée aux cas d'utilisation marginaux.
### Interception par homme du milieu
La solution de l'homme du milieu est relativement simple. Il vous suffit de trouver dans la documentation les sections sur l'installation du certificat de l'homme du milieu et la configuration du proxy, et de l'utiliser avec mitmproxy. Si vous n'êtes pas du tout familier avec cela, vous pouvez vous référer à notre script officiel startmitm.py, qui contient déjà toute la logique nécessaire que vous pouvez copier ou réutiliser à tout moment.
### Interception par Hook
La solution de Hooking nécessite que vous ayez des compétences de niveau débutant ou supérieur en ingénierie inverse. Si vous n'en avez jamais entendu parler auparavant, vous n'avez pas besoin de considérer cette solution pour le moment. En résumé, la solution de Hooking consiste à écrire des scripts Frida pour intercepter les appels de fonctions pertinents, obtenir les paramètres ou les valeurs de retour et les soumettre, puis les injecter dans l'application. Vous pouvez trouver une démo simple et des instructions d'utilisation dans le chapitre "Utiliser Frida pour rapporter des données".
### Code d'automatisation
Bien sûr, le code d'automatisation est également un élément indispensable, car vous en avez besoin pour déclencher la logique appropriée. Pour écrire du code d'automatisation, votre flux de travail devrait généralement être le suivant. Tout d'abord, vous devez ouvrir le bureau à distance de FIREPRA. Vous devriez voir une interface comme celle-ci.
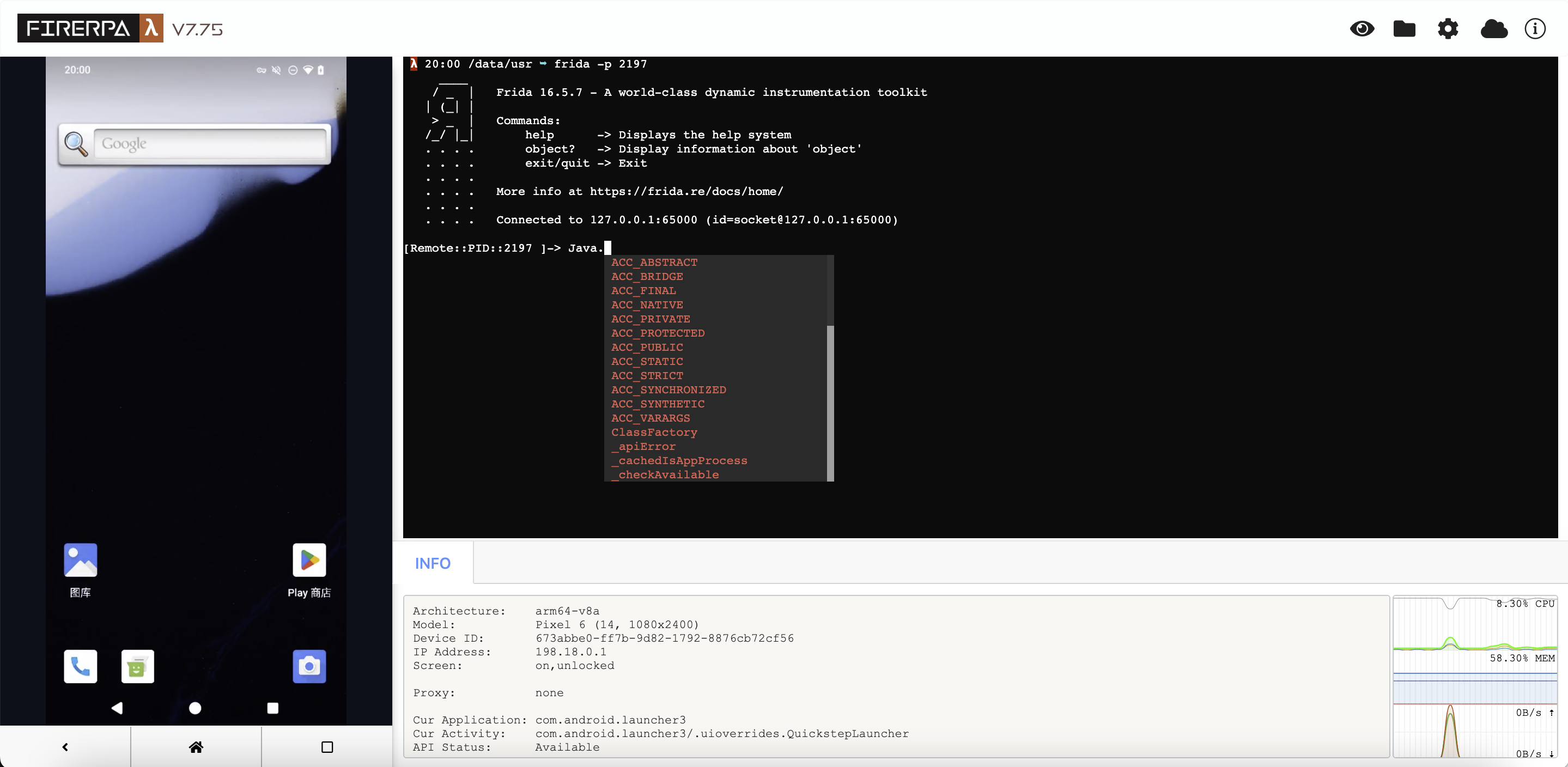
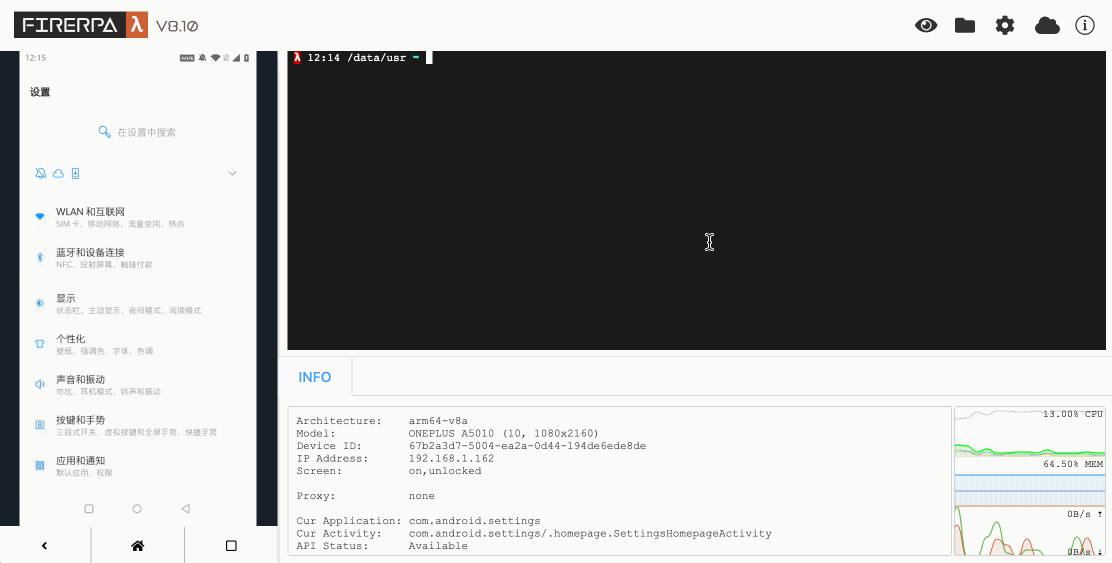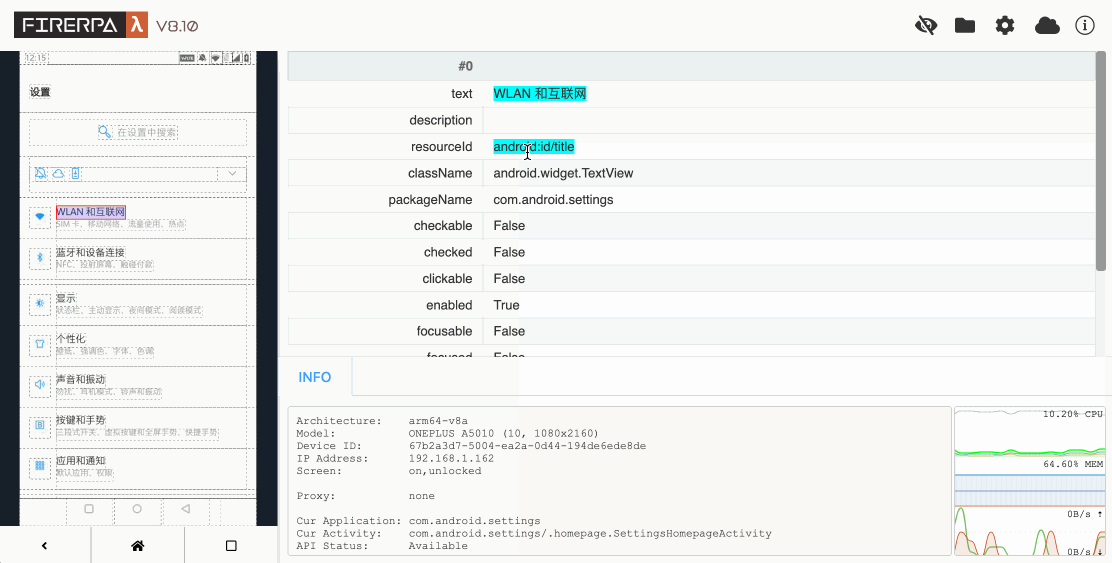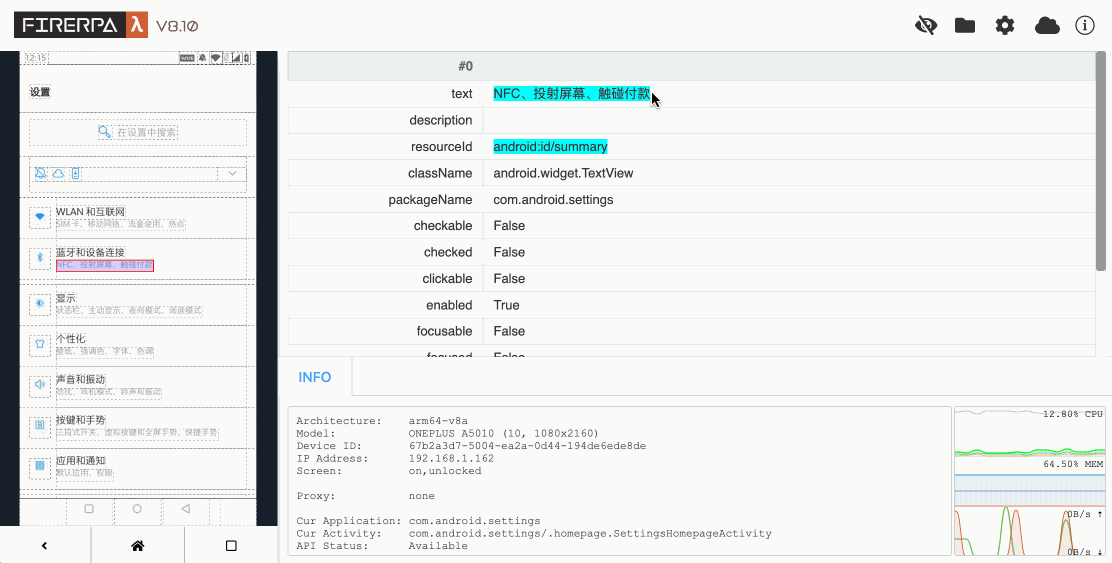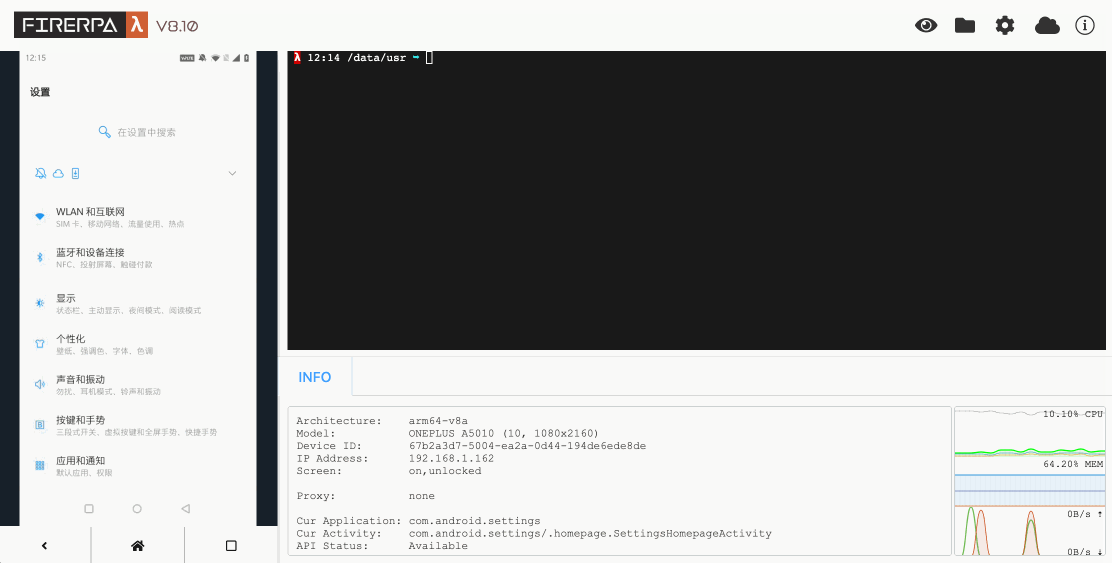
Maintenant, veuillez ouvrir l'application que vous souhaitez automatiser, puis cliquez sur l'icône en forme de petit œil dans le coin supérieur droit du bureau à distance. Vous verrez l'interface suivante. À ce stade, sélectionnez l'élément que vous souhaitez manipuler et cliquez dessus pour voir ses informations.
```{tip}
Bien sûr, vous pouvez aussi l'ouvrir avec du code, tout cela sera expliqué plus tard.
```
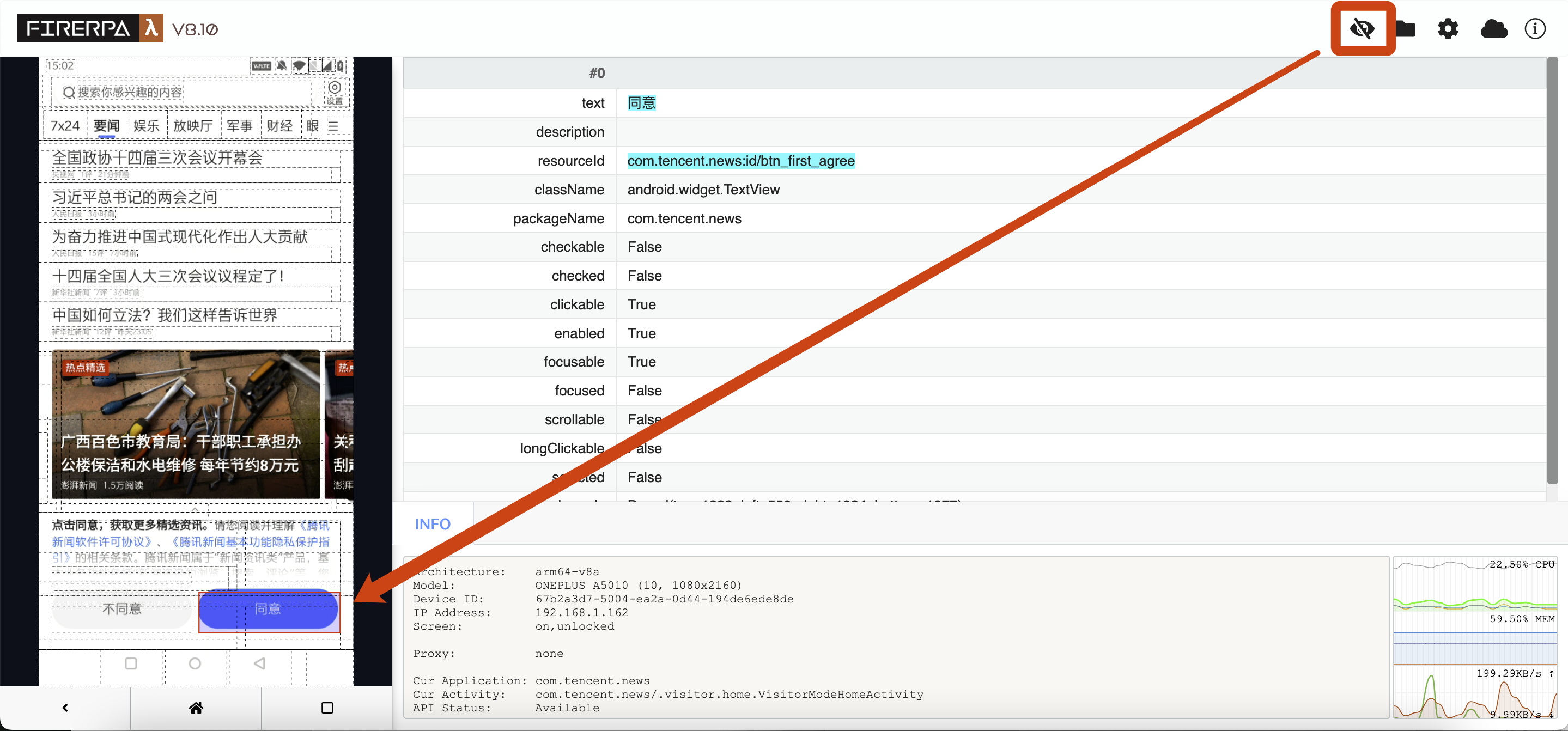
Vous pouvez voir les informations de l'élément sur la droite, telles que `text`, `resourceId`, etc. Maintenant, si nous voulons cliquer sur cet élément, nous écrivons le code suivant. La signification de ce code est "cliquer sur l'élément dont le texte est '同意' (Accepter)".
```python
d(text="同意").click()
```
```{note}
Ceci n'est qu'un exemple. Il existe de nombreuses façons d'écrire des sélecteurs. Cet exemple ne présente que la plus simple.
```
Voilà, vous connaissez maintenant la méthode la plus simple. Maintenant, veuillez écrire la logique de contrôle comme `if else`, en combinaison avec d'autres interfaces comme `exists`, et vous pourrez mettre en œuvre un processus d'automatisation complet. Vous voyez, ce n'est pas si difficile.
## Inspection de la mise en page de l'interface
Normalement, l'écriture de code d'automatisation est indissociable de l'inspection de la mise en page de l'interface, qui est le seul moyen d'obtenir les conditions pour vos sélecteurs. Tout d'abord, vous devez ouvrir le bureau à distance de l'appareil dans votre navigateur. Ensuite, cliquez sur l'icône en forme d'œil dans le coin supérieur droit du bureau à distance pour entrer en mode d'inspection de la mise en page. Vous pouvez alors cliquer sur les cadres en pointillés sur l'écran de gauche pour afficher les informations de l'élément correspondant. Vous pouvez utiliser ses attributs comme paramètres pour votre sélecteur. Un nouveau clic sur l'icône de l'œil fermera l'inspection de la mise en page. L'inspection de la mise en page ne se rafraîchit pas avec les changements de page ; elle représente toujours la mise en page de l'écran au moment où vous avez appuyé sur le raccourci. Si vous avez besoin de rafraîchir la mise en page, veuillez appuyer manuellement sur le raccourci `CTRL + R`.
```{hint}
Vous pouvez également appuyer sur la touche TAB dans l'interface d'inspection de la mise en page pour parcourir tous les éléments.
```
## Sélecteur d'interface
Le sélecteur d'interface (`Selector`) est utilisé pour manipuler les éléments Android. Vous pouvez le considérer comme une règle Xpath ; bien qu'ils soient différents, leur objectif est globalement le même. Dans FIRERPA, le sélecteur est `Selector`, mais dans la plupart des cas, vous n'aurez pas à interagir directement avec cette classe. Vous avez déjà dû voir cet élément dans le texte précédent. Il inclut les paramètres optionnels suivants :
| Type de correspondance | Description |
|-------------------------------|-------------------------------------------|
| text | Correspondance exacte du texte |
| textContains | Le texte contient la chaîne spécifiée |
| textStartsWith | Le texte commence par la chaîne spécifiée |
| className | Correspondance du nom de la classe |
| description | Correspondance exacte de la description |
| descriptionContains | La description contient la chaîne spécifiée |
| descriptionStartsWith | La description commence par la chaîne spécifiée |
| clickable | Est cliquable |
| longClickable | Permet un clic long |
| scrollable | Est défilable |
| resourceId | Correspondance de l'ID de ressource |
Dans la plupart des cas, seuls `resourceId`, `text`, `description`, `textContains`, etc., sont utilisés comme paramètres. Si un élément a un `resourceId` normal, il est préférable de l'utiliser comme sélecteur, par exemple `d(resourceId="com.xxx:id/mobile_signal")`. Sinon, on utilisera `text`, comme `d(text="Cliquer pour entrer")`, ou de manière plus vague `d(textContains="Cliquer")`. `description` est similaire à `text`, mais est moins fréquemment utilisé.
```{hint}
Le sélecteur (`Selector`) est construit à partir des principaux paramètres que vous obtenez via la fonction d'inspection de la mise en page de l'interface décrite ci-dessus.
```
## Définition des coordonnées de l'écran
Au cours des opérations d'automatisation, il est inévitable de devoir opérer en utilisant des coordonnées détaillées ou des coordonnées de zone. Cependant, comme beaucoup de gens ne sont peut-être pas très familiers avec les problèmes de coordonnées, nous allons présenter ici les connaissances sur les coordonnées de l'écran Android.
Comme chacun sait, les images ont une résolution, et les écrans aussi. Pour un écran Android, qu'il soit en mode portrait, paysage ou en rotation automatique, le coin supérieur gauche est toujours considéré comme l'origine (0,0) d'un système de coordonnées qui s'étend vers la droite et vers le bas. X est l'axe horizontal et Y est l'axe vertical, comme illustré.
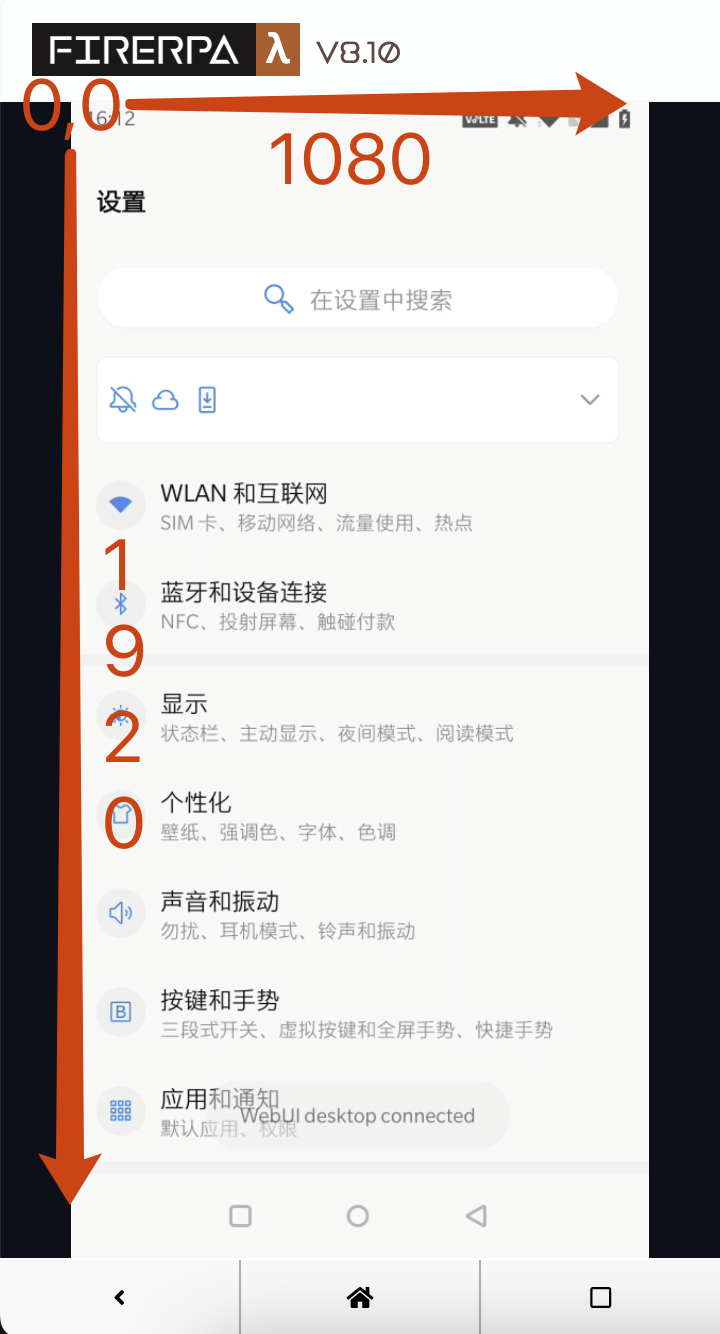
D'après la figure ci-dessus, les coordonnées du coin supérieur gauche de l'écran sont (0,0), celles du coin supérieur droit sont (1080,0), celles du coin inférieur gauche sont (0,1920) et celles du coin inférieur droit sont (1080,1920). Vous pouvez utiliser ces informations pour calculer les coordonnées de n'importe quel point sur l'écran.
```{note}
Que l'écran soit nativement en mode portrait ou paysage, ou qu'il soit en rotation automatique, le coin supérieur gauche de l'orientation actuelle de l'écran est toujours considéré comme l'origine.
```
### Un point sur l'écran
Dans FIRERPA, il existe deux définitions relatives à l'écran. Certaines opérations comme le clic ou la capture d'écran nécessitent que vous fournissiez des informations de zone ou de coordonnées. Pour un point de coordonnées commun, nous utilisons la définition suivante, qui représente le point aux coordonnées (100,100) de l'écran.
```python
Point(x=100, y=100)
```
### Définition d'une zone
La définition d'une zone correspond à une région rectangulaire sur l'écran. Sa définition est un peu plus complexe, veuillez la lire attentivement. Nous utilisons `Bound` pour représenter une zone sur l'écran. Il nécessite que vous fournissiez quatre paramètres : `top`, `left`, `bottom` et `right`. Vous pourriez être un peu confus, alors veuillez lire attentivement ce qui suit : `top` représente la distance en pixels entre le bord supérieur du rectangle et le bord supérieur de l'écran, `left` représente la distance en pixels entre le bord gauche du rectangle et le bord gauche de l'écran, `right` représente la distance entre le bord droit du rectangle et le bord gauche de l'écran, et `bottom` représente la distance entre le bord inférieur du rectangle et le bord supérieur de l'écran. En bref, vous pouvez comprendre que toutes les distances sont relatives aux axes X et Y partant de l'origine. Utilisons une figure pour vous aider à comprendre. L'écran du téléphone est toujours de 1080x1920, et l'appareil est actuellement en mode portrait.

Supposons maintenant que l'écran est divisé en quatre parties égales et que nous devons obtenir la définition des deux zones illustrées, en haut à gauche et en bas à droite. Selon les règles, pour la zone 1, le bord supérieur du rectangle est à 0 pixel du haut de l'écran, le bord gauche est à 0 pixel de la gauche de l'écran, le bord inférieur est à 960 pixels du haut de l'écran (1920÷2), et le bord droit est à 540 pixels de la gauche de l'écran (1080÷2). Sa définition devrait donc être :
```python
Bound(top=0, left=0, right=540, bottom=960)
```
De même, pour la zone 2, le bord supérieur du rectangle est à 960 pixels du haut de l'écran, le bord gauche est à 540 pixels de la gauche de l'écran, le bord droit est à 1080 pixels de la gauche de l'écran, et le bord inférieur est à 1920 pixels du haut de l'écran. On peut donc en déduire que la définition du second rectangle est :
```python
Bound(top=960, left=540, right=1080, bottom=1920)
```
## Données des applications Android
Chaque application Android sur un appareil dispose d'un répertoire dédié pour stocker ses données. En général, les données de l'application sont stockées dans le répertoire `/data`. Vous pouvez obtenir le répertoire de données d'une application en appelant l'interface `d.application("com.example").info()`. Dans la plupart des cas, vous pouvez également vous rendre directement dans le répertoire utilisateur en faisant `cd /data/user/0/com.example.test`. En plus du répertoire `/data` classique, certaines applications stockent également des fichiers multimédias et autres dans le répertoire `/sdcard/Android`.
### Consulter la base de données des SMS
Parfois, vous pourriez vouloir savoir où sont stockés les SMS reçus sur votre appareil. C'est une excellente idée, et c'est très simple. Vous pouvez même écrire une extension pour lire directement le contenu et l'obtenir en temps réel via une interface HTTP !
Nous allons suivre l'approche standard d'Android. Si votre cas est différent, n'hésitez pas à adapter votre raisonnement. Sur Android, le nom de l'application de messagerie devrait être `com.android.mms`, nous pouvons donc nous rendre directement dans le répertoire `/data/user/0/com.android.mms`. Grâce à l'opération ci-dessous, vous pouvez voir qu'il y a plusieurs bases de données dans le répertoire `databases`, et `mmssms.db` est notre cible.
```text
λ 10:12 /data/user/0/com.android.mms ➥ ls -la
total 82
drwx------ 7 u0_a78 u0_a78 3452 Jan 2 2021 .
drwxrwx--x 381 system system 53248 May 2 16:46 ..
drwxrws--x 3 u0_a78 u0_a78_c 3452 Jan 2 2021 cache
drwxrws--x 2 u0_a78 u0_a78_c 3452 Jan 2 2021 code_cache
drwxrwx--x 2 u0_a78 u0_a78 3452 Jan 2 2021 databases
drwxrwx--x 7 u0_a78 u0_a78 24576 Feb 26 13:43 files
drwxrwx--x 2 u0_a78 u0_a78 3452 May 4 10:12 shared_prefs
λ 10:12 /data/user/0/com.android.mms ➥ ls -l databases/
total 504
-rw-rw---- 1 u0_a78 u0_a78 24576 Jan 2 2021 dynamic_bubble
-rw------- 1 u0_a78 u0_a78 0 Jan 2 2021 dynamic_bubble-journal
-rw-rw---- 1 u0_a78 u0_a78 491520 Feb 27 04:18 mmssms.db
-rw------- 1 u0_a78 u0_a78 0 Jan 2 2021 mmssms.db-journal
λ 10:12 /data/user/0/com.android.mms ➥
```
Bien sûr, la lecture est très simple, car sous Android, les bases de données des applications standard sont généralement au format SQLite. Cependant, les applications à haute sécurité chiffrent souvent leurs propres bases de données. Mais FireRPA est si puissant, comment pourrait-il ne pas avoir cette fonctionnalité ? FireRPA peut non seulement lire les bases de données SQLite standard, mais il prend également en charge la **lecture en temps réel** de divers types de bases de données comme celles de WeChat (sqlcipher) aes-256, WeChat Work aes-128, et les bases de données du groupe Alibaba sqlcrypto (aes-128) (à condition que vous trouviez la clé vous-même). Ci-dessous, nous allons simplement vous montrer comment lire le contenu des SMS du système. C'est très simple, une seule commande suffit. Bien sûr, vous pouvez aussi écrire une extension pour le faire.
```bash
sqlite3 databases/mmssms.db .dump
```
Bien sûr, la sortie sera volumineuse, mais vous pourrez y trouver rapidement la table contenant les données dont vous avez besoin, puis utiliser SQL vous-même. Cette méthode fonctionne pour 98% des applications Android, les 2% restants étant des bases de données chiffrées.
### Consulter les bases de données chiffrées
Pour ces bases de données chiffrées, vous devez trouver vous-même la clé de la base de données ou la manière dont elle est calculée et générée. Ci-dessous, nous vous expliquons brièvement comment lire les bases de données de certains logiciels. Nous ne montrerons que comment utiliser `PRAGMA` pour prédéfinir la clé. Si vous ne comprenez pas ce que c'est, veuillez d'abord vous renseigner sur SQLite.
> Série WeChat (sqlcipher)
```sql
PRAGMA cipher = "sqlcipher";
PRAGMA legacy = 1;
PRAGMA key = "database-key";
```
> WeChat Work (wxsqlite)
```sql
PRAGMA cipher = "aes128cbc";
PRAGMA hexkey = "database-key"
```
> Série Alibaba (sqlcrypto)
```sql
PRAGMA cipher = "sqlcrypto";
PRAGMA key = "database-key"
```
```{hint}
Les bases de données des applications Android ne se trouvent pas nécessairement dans le répertoire `databases`.
```
### Consulter d'autres données
Bien sûr, le répertoire de données d'une application ne contient pas que des bases de données. Il contient également des paramètres, des configurations, des caches et des fichiers liés à l'application, tels que `shared_prefs` (xml), etc. Nous n'entrerons pas dans les détails, vous pouvez explorer par vous-même.
## Mesures d'assistance à l'automatisation
Dans le domaine de l'automatisation, toutes les applications ne se prêtent pas à la localisation par sélecteurs. Certaines interfaces, comme celles des jeux, sont rendues en temps réel et n'ont pas de mise en page au niveau d'Android. Pour ce type d'applications, vous ne pouvez utiliser que l'OCR ou la correspondance d'images pour la reconnaissance des opérations. Nous fournissons une solution d'assistance OCR complète ainsi que des solutions intégrées de correspondance d'images SIFT et de correspondance de modèles pour vous aider à atteindre ces objectifs métier. Vous pouvez trouver les interfaces correspondantes et leurs méthodes d'utilisation dans la documentation.
Mise à jour en cours...